Serving Agentic Workloads at Scale with vLLM x Mooncake
·10 min read
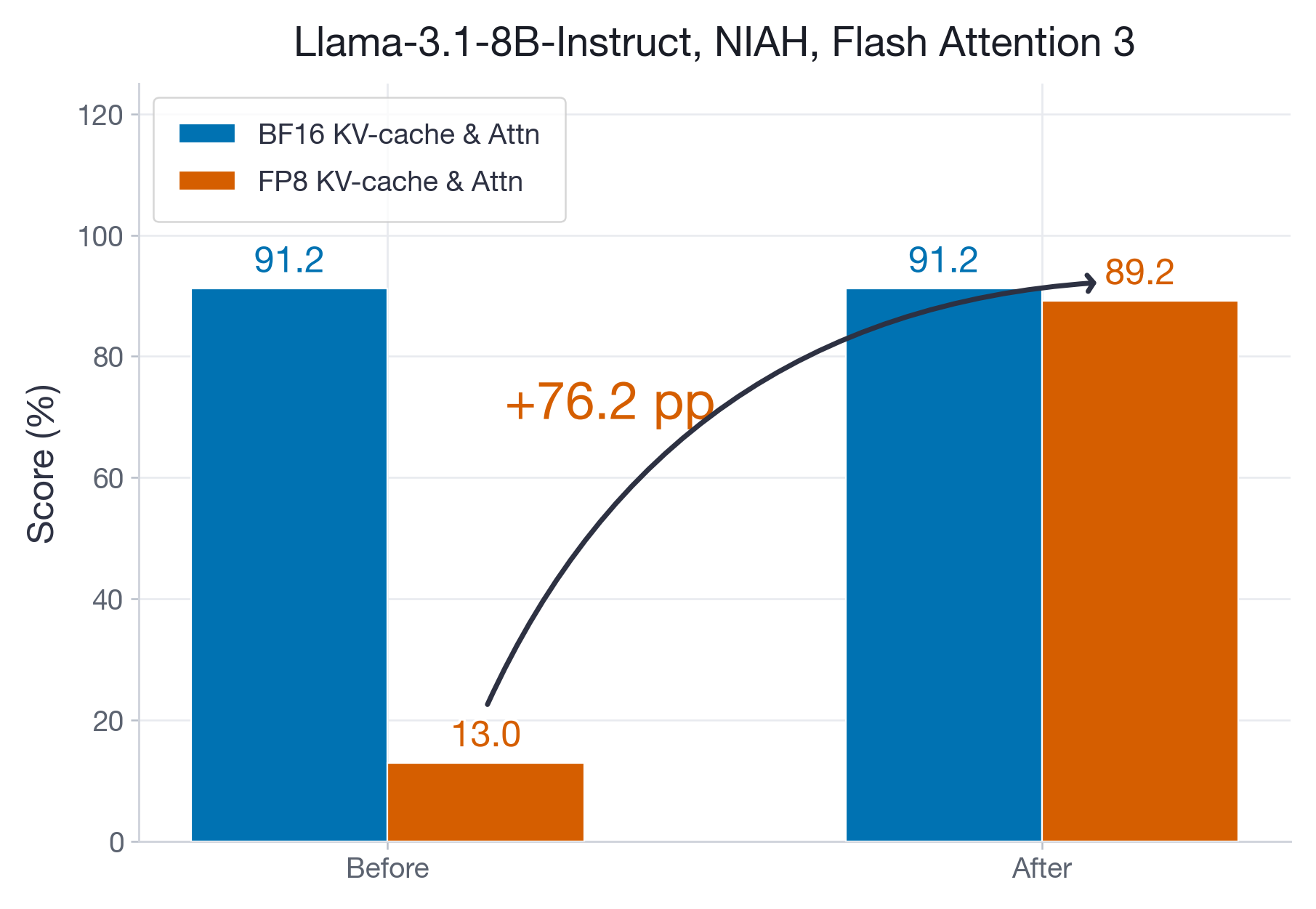
TL;DR: Agentic workloads generate massive shared prefixes that are often recomputed across turns. By integrating Mooncake's distributed KV cache store into vLLM, we achieve 3.8x higher throughput,...