Serving Agentic Workloads at Scale with vLLM x Mooncake

TL;DR: Agentic workloads generate massive shared prefixes that are often recomputed across turns. By integrating Mooncake's distributed KV cache store into vLLM, we achieve 3.8x higher throughput, 46x lower TTFT, and 8.6x lower end-to-end latency on realistic agentic traces, while scaling nearly linearly to 60 GB200 GPUs.
Agentic workloads are reshaping LLM serving
With the rise of LLM agents such as Claude Code and OpenClaw, inference workloads are undergoing a fundamental shift. As Jensen highlighted in his GTC 2026 keynote, LLMs are moving beyond simple chatbots toward autonomous, long-running systems that plan, reason, and act toward complex goals.
What makes agentic workloads unique is their structure. They typically consist of long-horizon, multi-turn loops that alternate between a reasoning step, where the model processes context and produces intermediate thoughts, and an action step, where the model issues tool calls and receives external outputs.
To quantify this behavior, we collected and analyzed traces from Codex and GPT-5.4 on the SWE-bench Pro dataset. We have also open-sourced the dataset here to encourage broader community study of agentic serving workloads.
Figure 1 summarizes the Codex/SWE-bench Pro traces and shows a representative agentic session.

The pattern is striking: by turn 30, context length grows to roughly 80K tokens, and the longest contexts can grow beyond 180K tokens. Yet each turn typically introduces only a few hundred to a few thousand new tokens. The rest is prefix that the model has already seen. Across the dataset, the average input-to-output token ratio is roughly 131:1.
If we can cache those prefixes, prefill for the cached portion becomes essentially free. The true per-turn cost is only the new delta.
Across the Codex/SWE-bench Pro dataset, comprising 610 traces with a median of 33 turns per trace, we observe:
- 94.2% cache hit rate
- 131:1 input-to-output ratio
- Average context growth of roughly 2,242 tokens per turn
- Median context growth from 12K to 80K tokens per trace
- Inter-turn delays ranging from 5.2s median to 81.4s P99
However, local KV cache offloading to CPU DRAM or disk runs into two major limitations for agentic workloads.
- Limited capacity and eviction. A 100K-token context can occupy GBs of storage (e.g., ~3.8 GB for Kimi-2.5 FP8 KV caches). On a busy instance serving many long-running sessions, these large prefix caches can quickly saturate local capacity and trigger eviction.
- Cross-instance misses. To balance load, the router may not always schedule the next turn of a session on the same vLLM instance. If the session is migrated to a different instance, that instance has never seen the prefix and must recompute it from scratch.
Takeaway: we can no longer treat an inference service as a set of isolated vLLM replicas. For agentic workloads, instances need to share a distributed KV cache pool that provides both larger aggregate capacity and cross-instance cache hits.
Distributed KV cache pool with Mooncake Store
Mooncake is an open-source, high-performance library for KV cache transfer and distributed storage. vLLM has already adopted Mooncake for prefill-decode (PD) disaggregation via the MooncakeConnector, using Mooncake's transfer engine to move KV caches between GPUs. Now, we take that integration one step further by building a distributed KV cache pool with Mooncake Store.
Figure 2 depicts the overall design.

At a high level, Mooncake Store offers a master server and a set of clients. The master server runs cluster-wide and manages metadata, including KV block hashes, sizes, etc. It also monitors client health and availability, providing service discovery and dead-node cleanup.
Mooncake clients run on GPU nodes where they manage local CPU/DRAM/SSD resources. Clients connect to one another through RDMA for KV cache transfer. Together, they form a distributed KV cache pool.
The vLLM integration plugs into the existing KVConnector interface, the same abstraction used for PD disaggregation. The connector has two roles:
On the scheduler side, when a new request arrives, vLLM hashes the prompt’s token blocks, queries the Mooncake master for matching KV cache blocks, and uses the result to guide scheduling decisions.
On the worker side, vLLM embeds a Mooncake client in each GPU worker and launches background threads for data movement. GPU KV cache memory is registered as RDMA buffers, enabling GPUDirect RDMA reads and writes through the Mooncake client without using SMs or staging through CPU memory.
Design highlights
SM-free and zero-copy KV transfer with GPUDirect RDMA
Conventionally, GPU-to-CPU data transfer is handled either by cudaMemcpyAsync, which uses GPU copy engines but may deliver suboptimal throughput for many small transfers, or by launching dedicated GPU kernels that copy data using SMs. Kernel-based copying can work well for large numbers of small transfers, but it can also interfere with other kernels running on the GPU.
We take a third approach: using the RDMA NIC and GPUDirect RDMA to move KV blocks directly between GPU HBM and CPU memory. This path requires no staging buffer and does not consume SMs. It also performs well for large numbers of small KV block transfers.
Thanks to the Mooncake Transfer Engine, the transfer path can also leverage multiple RNICs on a node through multi-NIC pooling and topology-aware path selection. This allows KV transfers to aggregate and better utilize available network bandwidth across NICs.
Fully asynchronous transfer
Although RDMA operations are asynchronous, preparing descriptors and issuing RDMA reads and writes still requires non-trivial CPU work. This overhead grows with sequence length because longer sequences contain more KV blocks.
To avoid blocking the main CPU path, which can delay GPU kernel launches, all RDMA operations run on a dedicated background I/O thread. From vLLM's perspective, this makes the transfer path fully asynchronous.
Enabling PD + distributed KV cache pool with MultiConnector
The integration also naturally extends to PD disaggregation through the MultiConnector interface. As shown in Figure 3, MultiConnector is a wrapper that chains multiple sub-connectors together. Each connector operates independently and does not rely on the others.
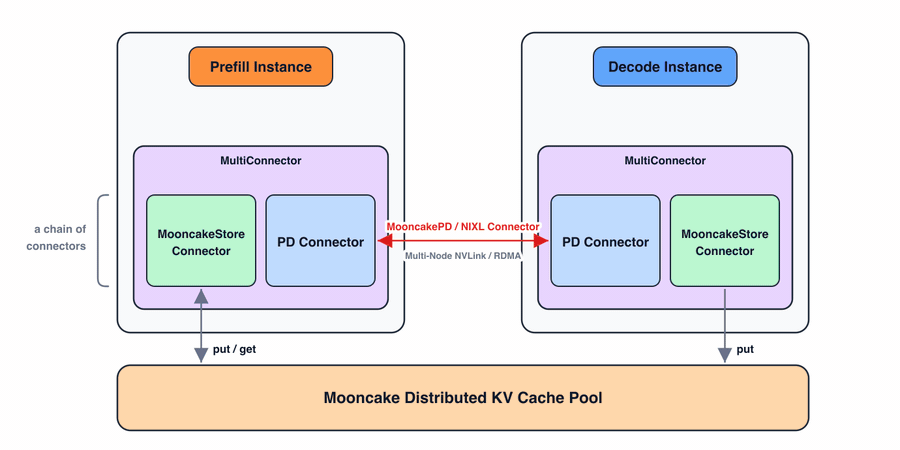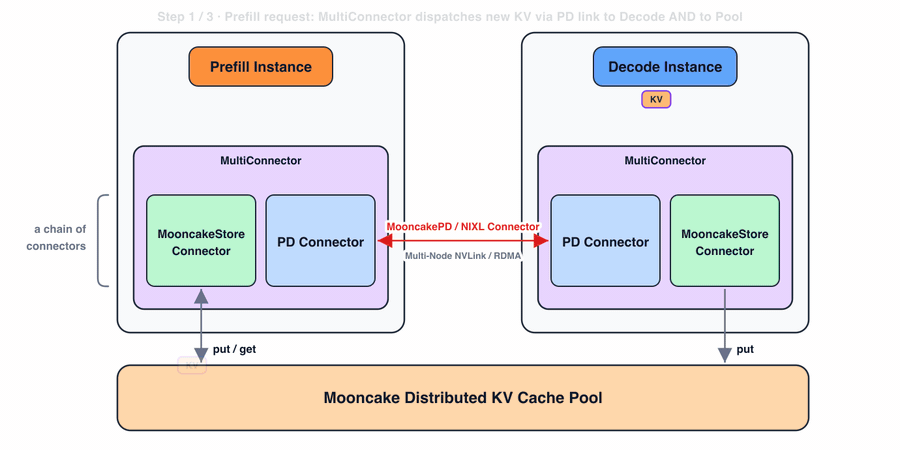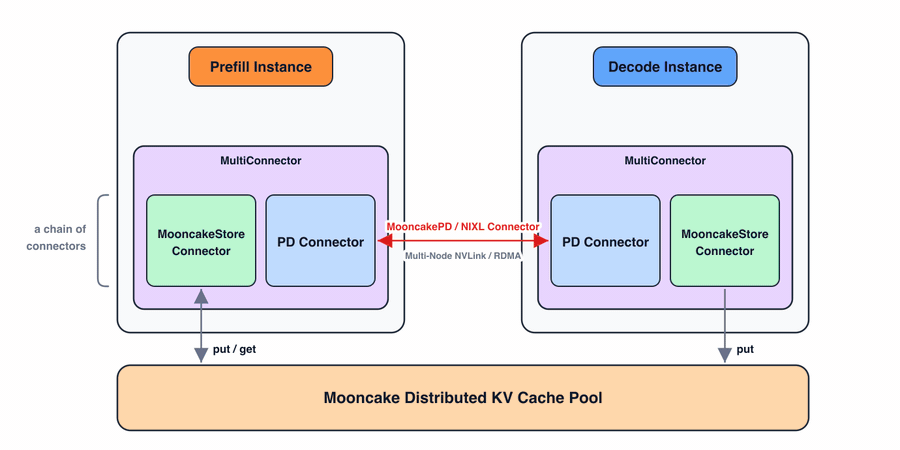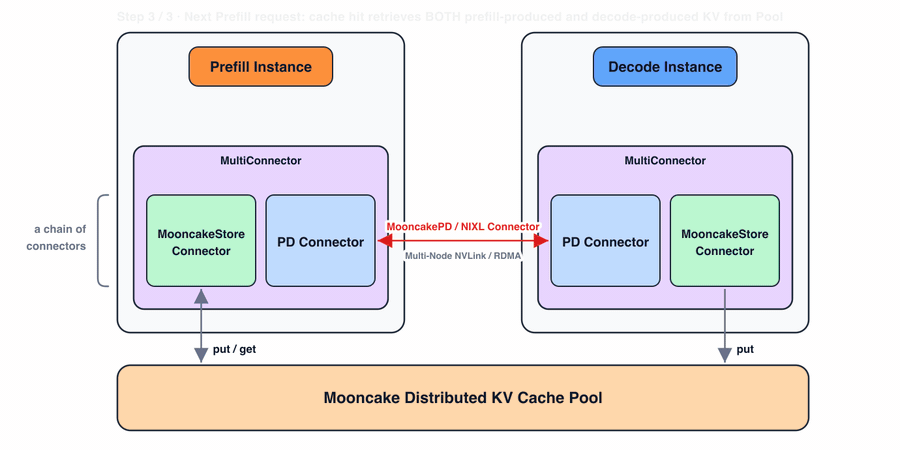
Prefill: The prefill instance prepares KV blocks for the PD connector and also stores them in the distributed KV cache pool through the store connector. For cache hits, vLLM queries all connectors and can recover matching prefixes from the Mooncake Store connector.
Decode: When the decode instance writes KV blocks into the distributed pool, they immediately become visible to prefill instances. Decode itself does not currently read from the pool: because vLLM schedules each request to both a prefill and a decode instance, the prefill instance loads any prefix KV blocks from the pool and forwards them to decode through the PD connector.
We are working to enable multi-path KV cache loading from both the prefill instance and the distributed pool, which would maximize available network bandwidth.
Performance
The current implementation is available here. We also provide benchmark scripts in the artifact repository here. In this post, we highlight two results.
We ran the Kimi-2.5 NVFP4 model on GB200 nodes with PD disaggregation. The prefill instance used TP4, while the decode instance used DP8 + EP. We found that this configuration provided the best latency-throughput tradeoff.
Speeding up real agentic traces
We first evaluated vLLM in a realistic setting using the Codex agentic traces described earlier. In this experiment, we deployed the model with 1P1D, using 12 GPUs in total.
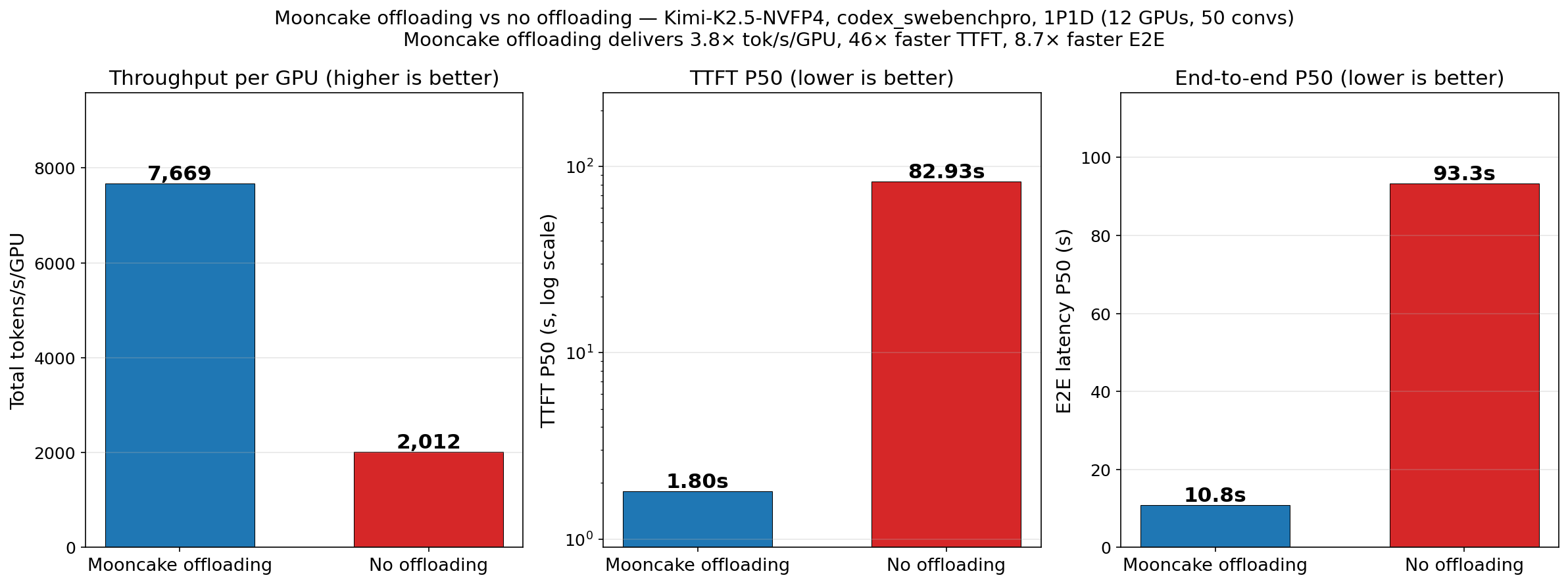
The distributed KV cache pool improves vLLM throughput by 3.8x and reduces P50 TTFT and E2E latency by 46x and 8.6x, respectively. These gains are driven by a dramatic increase in cache hit rate: from 1.7%, where only the system prompt is cached, to 92.2%, where nearly the entire prefix is cached.
Scaling out to multiple nodes
For the scalability test, we further increased the number of nodes and used a synthetic dataset derived from the Codex workload for controlled scaling experiments.
Experiment settings:
- 20K common tokens (system instructions)
- 10K tokens first input
- 2,048 tokens per-turn input length
- 900 output tokens
- 30 turns total
- Number of sessions scaled with number of GPUs: 75 → 150 → 225 → 300 → 375
- Parameters were chosen to roughly align with the original Codex workload and keep the total output/input ratio ~1.3%
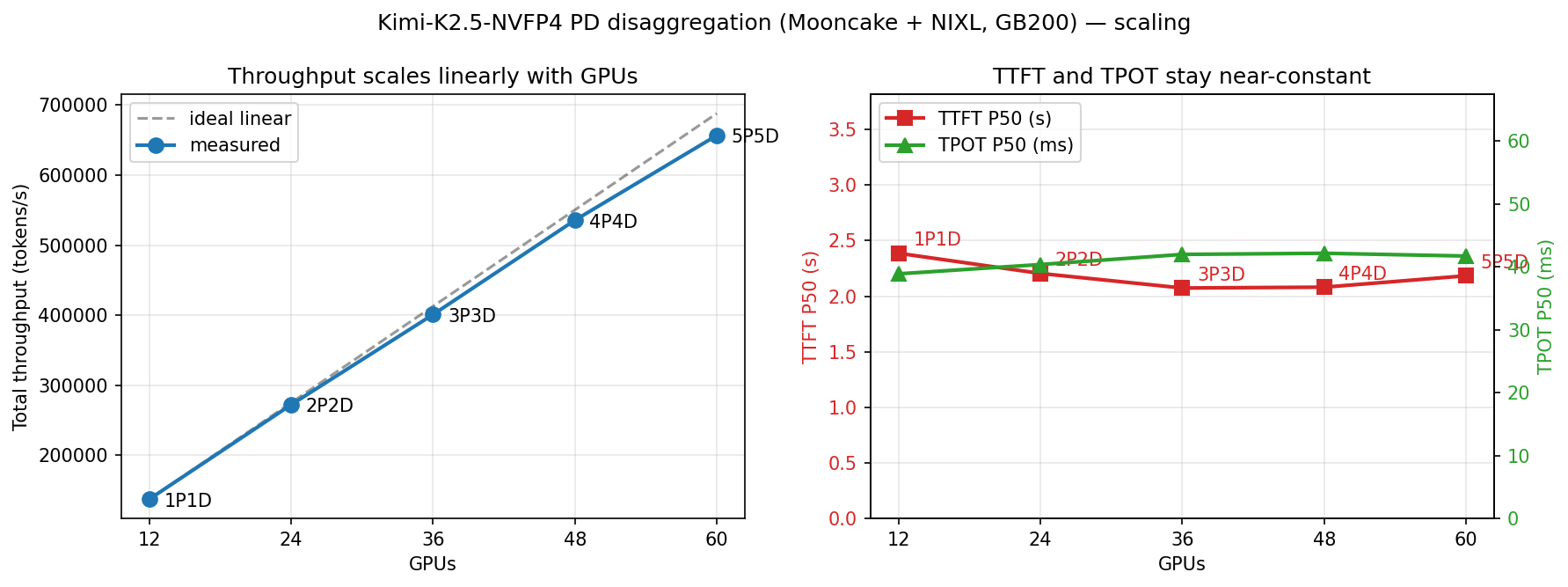
To stress-test the datapath under cross-node traffic, we used round-robin routing. As a result, requests could be scheduled on different nodes across turns and often needed to fetch KV caches from a previous node.
Without a distributed KV cache pool, this routing pattern would cause massive cache misses and severe throughput degradation. With Mooncake Store, vLLM consistently achieves a cache hit rate above 95%, and the system scales nearly linearly to 60 GPUs.
This result shows that the distributed KV cache pool substantially improves cache hit rate while maintaining an efficient datapath as the cluster grows.
What's next?
We are actively working on the following features and optimizations.
- Distributed disk offloading. Extend the storage hierarchy beyond CPU DRAM to NVMe SSDs and distributed file systems, enabling even larger cache capacity.
- KV cache offloading for hybrid models. Support emerging model architectures with mixed attention mechanisms, which may require different caching strategies across layers.
- Cache-aware routing. Co-design the request router with the KV cache pool so that turns are directed to instances that already hold the relevant prefix, maximizing local cache hits before falling back to the distributed pool.
- Further datapath optimization. Leverage NVIDIA multi-node NVLink in addition to RDMA for faster, multi-path KV cache transfer. We are also exploring DualPath-like simultaneous KV loading from both prefill and decode instances to maximize aggregate bandwidth.
Acknowledgements
The vLLM Mooncake Store integration was largely inspired by prior work in vLLM-Ascend. We are especially grateful to Chao Lei from Ant Group for the initial implementation, and to Zijing Liu from Inferact for the agentic trace and analysis.
We also thank Jiahao Lu, Zuoyuan Zhang, Zihan Tang, and Ke Yang from Approaching.AI; Pengbo Zhao, Fuqiao Duan, and Tianyu Xu from Huawei; Tianchen Ding, Xuchun Shang, Xingrui Yi, and Teng Ma from Alibaba Cloud Computing; Yunxiao Ning, Dejiang Zhu, and Shoujian Zheng from Ant Group; and Feng Ren from 9#AISoft for valuable technical feedback.
We are grateful to the broader vLLM and Mooncake communities for their support and suggestions. Finally, special thanks to the Inferact team for their close collaboration and discussions throughout this work.